Applied mathematics and reinforcement learning project in C++
MDP and Dynamic Programming in C++
Reusable C++ framework for Value Iteration on discrete decision problems
This project demonstrates algorithmic rigor and low-level implementation quality. It does not only solve a toy MDP once; it provides reusable abstractions for states, actions, transitions, rewards, and policy computation.
2
States
3
Actions
270%
Reward uplift
Problem
Understanding reinforcement learning foundations is easier when the algorithmic core is implemented from scratch rather than hidden behind high-level libraries.
Approach
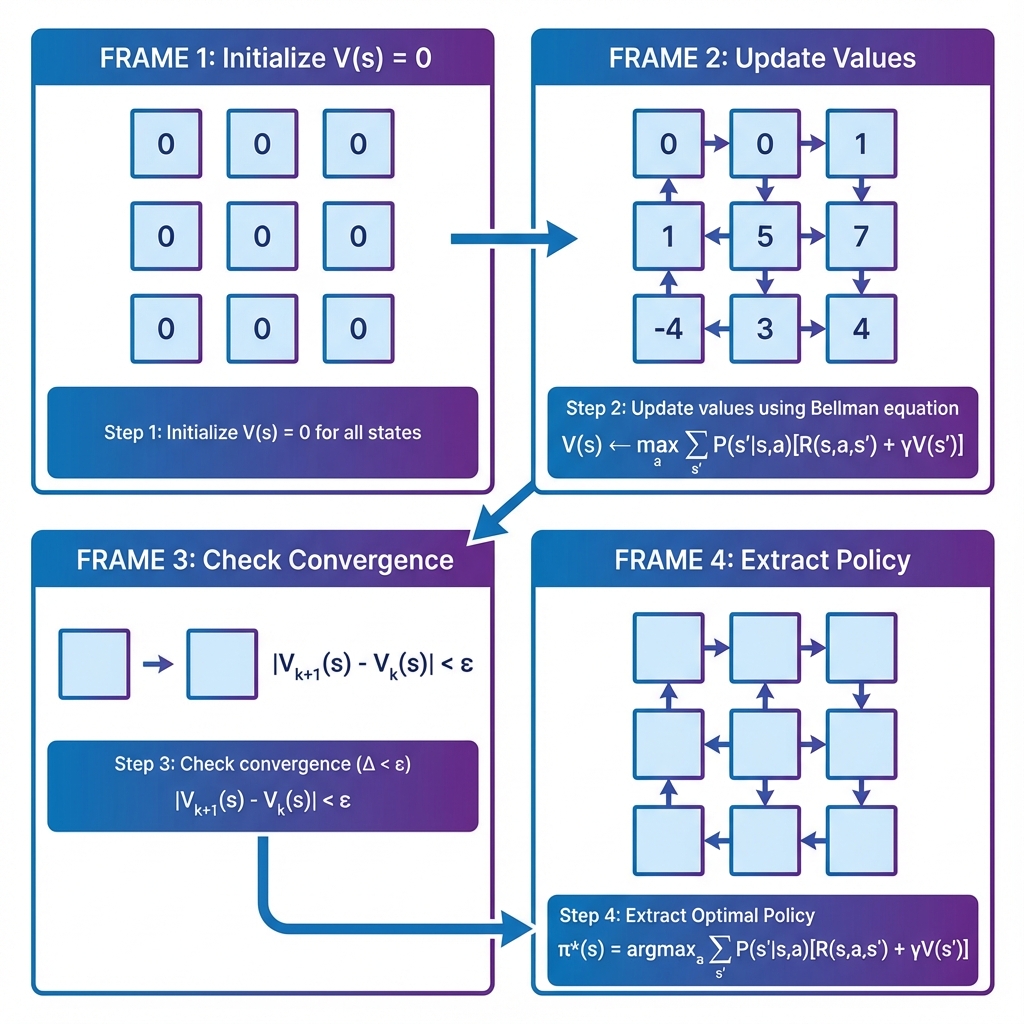
Built template-based MDP classes, implemented a perfect MDP representation, wrote a Value Iteration solver, added tests, and documented the robot example with diagrams and simulation visuals.
Results
The optimal robot policy outperformed a random policy by about 270 percent and converged in roughly 20 to 30 iterations.
What is in the repository
Role and scope
Algorithm implementation, systems programming, testing, and visualization support
Project context
Applied mathematics and reinforcement learning project in C++
Main stack